[how to] SQL Server does not exist or access denied from a VMWare guest |
- SQL Server does not exist or access denied from a VMWare guest
- Tag search + mysql + pagination
- Open source tools for Oracle schema compares
- SSIS 2012 Create environment variable fails
- Specific disadvantages to storing infrequently accessed large files in a large database
- Move multiple SQL Server 2008 databases from C: to D: at once
- How to optimize MySQL for large blob updates
- How to insert in table from remote stored procedure without creating a distributed transaction?
- One Form with Fields from two Tables [migrated]
- Mysql Select query takes too long for mutilple tables - 12 minutes
- Restore SQL Server 2000 Database in use
- Percona Playback - Strange Locking issues
- Best way to put checksum on all pages
- Start Oracle 12c enterprise manager in Windows 7
- Autogrowth of database with it's file name
- SQLServer audit query that fires a trigger
- Bulk database update/insert from CSV file
- Oracle db_name, db_unique_name, and ORACLE_HOME
- Altering the location of Oracle-Suggested Backup
- Database restructure - beneficial?
- Error while restoring a Database from an SQL dump
- MYSQL Timezone support
- replication breaks after upgrading master
- Custom sp_who/sp_whoUsers
- Need to suppress rowcount headers when using \G
- How to search whole MySQL database for a particular string
- multivalued weak key in ER database modeling
- Microsoft Office Access database engine could not find the object 'tableName'
- Sql Anywhere 11: Restoring incremental backup failure
| SQL Server does not exist or access denied from a VMWare guest Posted: 17 Jul 2013 08:33 PM PDT I've made the configuration to allow remote connections to SQL Server 2012, however I still cannot connect to it from a VMware Workstation Guest (using both NAT and Bridge). I can ping the host machine from the guest VM when using NAT (the same is not true for bridge config). Can you help me? |
| Tag search + mysql + pagination Posted: 17 Jul 2013 07:44 PM PDT I have a table "tags" in my database which will be updated with so many new rows every second... The user will be able to see the tags list in a page ordered by the added_time...I am trying to use limit and offset options of mysql...So It lists first "50 results" and a "show more" button...On clicking "show more" the next result set will be loaded... And it is possible that while clicking the "show more" button, some 10 tags have been newly added to the "tags" table... So there will be 10 rows from the "previous result set" shown in the "second result set" and it goes on like this... Is there any way to show the changes in the "first set" and then the second set? |
| Open source tools for Oracle schema compares Posted: 17 Jul 2013 04:28 PM PDT I'm looking for an open source tool to generate DDL scripts. Many tools call these synchronization scripts. We essentially want to compare schema of different environments (ie: DEV to QA, QA to PROD) to manage object migrations/deployments a little easier. Do open source tools exist like this for Oracle? |
| SSIS 2012 Create environment variable fails Posted: 17 Jul 2013 08:33 PM PDT I'm working a script to port an Environment from one server to another. I am running into an issue calling What's strange is that if I let the GUI script out the variables, that query would work However, taking this script approach isn't working. The legwork I've done indicates this error message is usually resolved by using nvarchar data type instead of varchar. However, that's not the case for my stuff. Line 108 for the following script. My assumption is that it's something wonky with the sql_variant but I have no idea what that thing is. |
| Specific disadvantages to storing infrequently accessed large files in a large database Posted: 17 Jul 2013 12:30 PM PDT I have heard many times across the web that it is, for various reasons, a bad idea to store files directly in a database, the preferred method being to store filenames in the database, and files directly on the filesystem. Most explanations, however, seem to assume that the stored files (in my case 2MB longtext object containing XML) are important to retrieve along with the query. I've seen a few comments in passing, however, that suggest that by storing these files directly in your database your are bloating it and thereby "interfere with IO or query performance of the rest of your database." Under what circumstances does this happen, and why? It is my understanding that blob and longtext over a certain size were stored externally anyways. Does the database still attempt to load up the entire longtext of an entry when it's respective row is used in operations? My main concern here comes from the fact that most of the queries of the table containing these rows of longtext do not actually need the longtext xml for anything. Does simply having these cumulatively massive chunks of data sitting in the same table really affect the performance of other queries against that table? |
| Move multiple SQL Server 2008 databases from C: to D: at once Posted: 17 Jul 2013 02:01 PM PDT I have SQL Server 2008 R2 with 323 databases consuming some 14 GB on my C: drive, a fast SSD. Because I want to reclaim some space on my C: drive, I would like to move them to my D: drive. I have found this MSDN article, but that seems to be the procedure to move only one database. Is there an automatic way or script to move all my databases at once? |
| How to optimize MySQL for large blob updates Posted: 17 Jul 2013 11:45 AM PDT I have a table that holds large BLOBs (up to 10M), and is updated frequently. The problem is that UPDATE statements can take up to 1 second to execute, and due to app design this blocks UI. I need to speed up those UPDATE/INSERT statements. Is there a way to do it by tuning MySQL server/storage engine/etc? The table in question is InnoDB, and I have tried turing compression on, but that didnt seem to make a lot of difference. Client is on the same machine as server so there is no network overhead. Server is MySQL 5.5 |
| How to insert in table from remote stored procedure without creating a distributed transaction? Posted: 17 Jul 2013 12:39 PM PDT How can I insert in a local table from a remote stored procedure without creating a distributed transaction, in SQL Server 2005? I want to run a stored procedure on a remote server and use the output as the source for an insert into a local table. |
| One Form with Fields from two Tables [migrated] Posted: 17 Jul 2013 10:34 AM PDT I am very new to Access 2007 and am trying to create one form which has multiple tabs on it. Four of the tabs represent information from one table and two of the tabs represent information from a second table. There is a relationship between the two tables: Enrollment Table!ID has a lookup relationship to Medical Info!ID Lookup. If there is a new record created using the form, which automatically assignes and ID to the client record in the Enrollment Table, I would like the a corresponding record to be automaticaly created in the Medical Info table. The problem I am having is that if I create a new client with the form, and move to the medical info table on the form, I can successfully display the ID Lookup results, however, no record is created in the medical info table unless I enter data into one field first. If this makes sense, is there a way to write the record to the Medical Info Table at the point that the Client ID is created, which would establish the relationship between "Client ID" and "ID Lookup" without having to enter into another field first? |
| Mysql Select query takes too long for mutilple tables - 12 minutes Posted: 17 Jul 2013 12:29 PM PDT Mysql query almost takes more than 12 minutes though indexing is in place. Please can you throw some light on how to bring down the response time. Thanks EXPLAIN for the above query is : |
| Restore SQL Server 2000 Database in use Posted: 17 Jul 2013 11:36 AM PDT I need to restore a SQL Server 2000 database to a backup of about 2 days ago. I have just backed it up and have tried to restore it, but it says it is in use. What is the best way to find out who is still using it and then how to disconnect them? I imagine taking the DB offline is a simple way of doing it, but probably not the safest? |
| Percona Playback - Strange Locking issues Posted: 17 Jul 2013 12:34 PM PDT Problem while replaying logsI am in the process of benchmarking a new DB node (specs at the end) and have run across some strange behavior: As described here i:
As per the documentation: This works fine for about 15 minutes, then I start getting strange locking problems: I started debugging my current load on the db and found that only one single query was running: (taken from innodb status) And only one table open: This situation stays like this for about 3-4 minutes and then suddenly playback continues. These issues do not happen on the live db: we have some issues with locking but we have never exceeded the innodb_lock_wait_timeout value. I am most likely missing something obvious but for the life of me i can't figure it out, but why would the replay hang like that or better yet why would mysql remain in this lock state? The relevant entries in the slow log are from our jee server: Does hibernate's transaction handling have anything to do with the way the lock is generated and not closed? Server Specs
Relavent config: Innodb config: Thanks for any help or experience in this area! |
| Best way to put checksum on all pages Posted: 17 Jul 2013 02:18 PM PDT I have a SQL Server database with the I'm looking for the best way to put checksums on at least all table and index data. My initial idea would be to drop and recreate all clustered indexes. For tables that have no clustered index I would create one and then drop it again. That should result in at least one write operation on each data and index page, but it's a bit heavy-handed. Anyone has a better idea? |
| Start Oracle 12c enterprise manager in Windows 7 Posted: 17 Jul 2013 01:19 PM PDT I have installed Oracle 12c in Windows 7. The installation was succesful and the RDBMS and the database that I created are working properly. Then I tried to access to the enterprise manager via web in If I type netstat I get: I am using a proxy but I disabled it for local locations. I tried this http://docs.oracle.com/cd/E25054_01/doc.1111/e24473/emctl.htm with no success because I couldn't find emctl file or the services it's talking about. I have 5 Oracle services running instead. Thanks in advance. |
| Autogrowth of database with it's file name Posted: 17 Jul 2013 09:54 AM PDT I use below query to get auto-growth event occurred to databases in a sql server. It outputs number of auto-growths,time taken for auto-growth and logical name of the file. But i want physical name of the file(mdf and ldf file name) instead of logical name.I don't know whether from sys.traces i will get physical name or please help me with an alternate way to do it. |
| SQLServer audit query that fires a trigger Posted: 17 Jul 2013 11:30 AM PDT Using SQLServer, does exist a way to audit from inside a trigger the sql that fires it? I need to know the SQL query that fires a trigger over a database without a profiler. Thanks |
| Bulk database update/insert from CSV file Posted: 17 Jul 2013 09:53 AM PDT I am implementing application specific data import feature from one database to another. I have a CSV file containing say 10000 rows. These rows need to be inserted/updated into database. There might be the case, where couple of rows may present in database that means those need to be updated. If not present in database, those need to be inserted. One possible solution is that, I can read one by one line, check the entry in database and build insert/update queries accordingly. But this process may take much time to create update/insert queries and execute them in database. Some times my CSV file may have millions of records. Is there any other faster way to achieve this feature? |
| Oracle db_name, db_unique_name, and ORACLE_HOME Posted: 17 Jul 2013 05:02 PM PDT I'm studying Oracle and I would like to understand the uniqueness or constrains when assigning these parameters. Suppose a machine with a single OS (host) and 2 different databases (physical). Are they forced to use different db_name in following cases?
How is this related when db_unique_name enters in the game? What's the point? So far reading in Forums and offical Docs I got the following assumption:
|
| Altering the location of Oracle-Suggested Backup Posted: 17 Jul 2013 09:58 AM PDT On one database, the Oracle-Suggested Backup scheduled from Enterprise Manager always ends up in the recovery area, despite RMAN configuration showing that device type disk format points elsewhere. As far as I can see, the scheduled backup job is simply: Asking RMAN to If I run the script manually, the backupset is placed at the above location, when the script is run from the job scheduler the backupset goes to the RECO group on ASM, Why might Oracle still choose to dump the backupset to the Ultimately, how can I change the backup destination? |
| Database restructure - beneficial? Posted: 17 Jul 2013 08:09 PM PDT I have a table for email messages. Then, I have a table that has the The At the time I used Parts to name the table and yet used field_id for the column. Just an FYI So for example, a My question is, will it be in my best interests to restructure the database? Id rather not. I was thinking about moving the Thanks |
| Error while restoring a Database from an SQL dump Posted: 17 Jul 2013 08:21 PM PDT I am extremely new to MySQL and am running it on Windows. I am trying to restore a Database from a dumpfile in MySQL, but I get the following error: I tried |
| Posted: 17 Jul 2013 02:21 PM PDT We are having a shared hosting plan and they are saying that do provide MYSQL Timezone support in a shared hosting plan. I can create timezone related tables in our database and populate them with required data(data from from our local MYSQL Timezone related tables. How to view the code syntax for MySQL "CONVERT_TZ" function? Thanks Arun |
| replication breaks after upgrading master Posted: 17 Jul 2013 11:21 AM PDT I have a set up of replication with master 5.1.30 and slave 5.5.16 and the replication is working good Now i have upgraded mysql master to 5.1.47 As far as i know we have to turn off the log bin with sql_log_bin=0 before using mysql_upgrade program in order to up grade the replication setup as well but the problem here is the binary log was not turned off while mysql_upgrade program is running The reason i found is in 5.1 the sql_log_bin is a session variable and mysql_upgrade program runs in another session so how to upgrade the replication as well along with the server with any breakage on replication setup. any suggestions are really useful..... |
| Posted: 17 Jul 2013 06:57 PM PDT I need to allow a client in a dev DW SQL 2K8R2 environment, to view and kill processes, but I do not want to grant VIEW SERVER STATE to this person (he's a former sql dba and is considered a potential internal threat). When I run the following, it returns one row as if the user ran the sp themselves with their current permissions. Changing the "with execute as" to "self" (I'm a sysadmin) returns the same results. I've also tried the below instead of calling sp_who, and it only returns one row. It seems that the context isn't switching, or persisting, throughout the execution of the procedure. And this is to say nothing of how I'm going to allow this person to "kill" processes. Does anyone have a solution or some suggestions to this seemly unique problem? |
| Need to suppress rowcount headers when using \G Posted: 17 Jul 2013 12:21 PM PDT Is there a command to suppress the rowcount headers and asterisks when using '\G' to execute a SQL statement? I am executing mysql with the |
| How to search whole MySQL database for a particular string Posted: 17 Jul 2013 03:21 PM PDT is it possible to search a whole database tables ( row and column) to find out a particular string. I am having a Database named A with about 35 tables,i need to search for the string named "hello" and i dont know on which table this string is saved.Is it possible? Using MySQL i am a linux admin and i am not familiar with databases,it would be really helpful if u can explain the query also. |
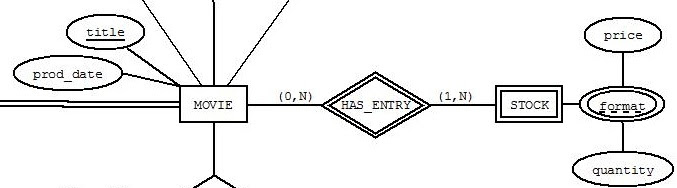
| multivalued weak key in ER database modeling Posted: 17 Jul 2013 01:21 PM PDT I was wondering since i didnt find out any clarification for this. I want to store movies that exist in different formats (dvd, bluray etc) and the price for each format differs from each other as well as the quantity of each format, so i came up with this: Is this correct from a design perspective? Does this implies redundancy? I dont understand how will this be stored in a table. Would it be better to do it like this : Thanks in advance. EDIT : I add some more descriptive information about what i want to store in this point of the design. I want to store information about sales. Each movie that exist in the company i need to store format, price and stock quantity. I will also need to store customer information with a unique id, name, surname, address, movies that he/she has already bought and his credit card number. Finally i will have a basket that temporary keeps items (lets suppose that other items exist apart from movies) that the customer wants to buy. |
| Microsoft Office Access database engine could not find the object 'tableName' Posted: 17 Jul 2013 05:21 PM PDT First a little background: I am using MS access to link to tables in an advantage database. I created a System DSN. In the past in Access I've created a new database, and using the exteranl data wizard, successfully linked to tables. Those databases and the linked tables are working fine. Now I am trying to do the same thing, create a new access db, and link to this same DSN. I get as far as seeing the tables, but after making my selection, I get the error, " The Microsoft Office Access database engine could not find the object 'tableSelected'. Make sure the object exists and that you spell its name and the path name correctly. I've tried creating another datasource (system and user) with no luck. Environment is Wn XP, Access 2007, Advantage DB 8.1 |
| Sql Anywhere 11: Restoring incremental backup failure Posted: 17 Jul 2013 09:54 AM PDT We want to create remote incremental backups after a full backup. This will allow us to restore in the event of a failure and bring up another machine with as close to real time backups as possible with SQL Anywhere network servers. We are doing a full backup as follows: This makes a backup of the database and log files and can be restored as expected. For incremental backups I've tried both live and incremental transaction logs with a renaming scheme if there are multiple incremental backups: However, on applying the transaction logs on restore I always receive an error when applying the transaction logs to the database:
The transaction log restore command is: The error doesn't specify what table it can't find but this is a controlled test and no tables are being created or dropped. I insert a few rows then kick off an incremental backup before attempting to restore. Does anyone know the correct way to do incremental backup and restore on Sql Anywhere 11? UPDATE: Thinking it may be related to the complexity of the target database I made a new blank database and network service. Then added one table with two columns and inserted a few rows. Made a full backup, then inserted and deleted a few more rows and committed transactions, then made an incremental backup. This also failed with the same error when attempting to apply the incremental backups of transaction logs after restoring the full backup ... Edit: You can follow this link to see the same question with slightly more feedback on SA: http://sqlanywhere-forum.sybase.com/questions/4760/restoring-incrementallive-backup-failure |

| You are subscribed to email updates from Recent Questions - Database Administrators Stack Exchange To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |

No comments:
Post a Comment